




 Bien préparer ses données avec Data Engineering d'ArcGIS Pro
Bien préparer ses données avec Data Engineering d'ArcGIS Pro


L'analyse de données est au coeur du système ArcGIS. Cela veut dire qu’il offre une large palette d'outils d'analyse, mais aussi tout l'outillage permettant l'intégration, le nettoyage et la mise en forme de ces données en amont de ces analyses. Ainsi, depuis ArcGIS Pro 2.7, Esri a ajouté une interface dédiée à l'ingénierie de la donnée (Data Engineering) pour rassembler les outils indispensables à la préparation de données, quelles soient spatiales ou non. Dans ce pas-à-pas, nous vous proposons, à travers un exemple concret, de découvrir quelques-unes des fonctionnalités proposées par les outils de Data Engineering d'ArcGIS Pro.
Pas-à-Pas réalisé par Gaëtan Lavenu (Esri France), en partenariat avec le blog arcOrama.fr
Pas-à-Pas réalisé par Gaëtan Lavenu (Esri France), en partenariat avec le blog arcOrama.fr


1- La première étape consiste tout d'abord à ouvrir l’application ArcGIS Pro avec les données souhaitées. Ici, nous utilisons un jeu de données issu de l'ADEME concernant les Diagnostics de Performance énergétiques (DPE) de logements pour le département du Calvados. Vous faites apparaitre les outils de Data Engineering à partir du menu contextuel sur la table ou en utilisant le raccourci clavier Ctrl+Maj+D.


2- L'interface de Data Engineering s'affiche alors. Elle est constituée d'un ruban spécifique avec différents outils de nettoyage, de création, d'intégration et de mise en forme de données. Dans la partie inférieure, un panneau présente la liste des champs. Vous pouvez glisser-déposer les champs dont vous voulez découvrir le contenu, puis cliquer sur le bouton " Calculer " pour générer les statistiques. Le panneau affiche alors, pour chaque champ, des informations comme le type de champ, le pourcentage de valeurs nulles, le diagramme de distribution des valeurs, les valeurs min/max/ moyenne, le nombre de valeurs uniques, etc.


3- Ces informations vont vous permettre de repérer un certain nombre de points relatifs à la qualité des données. Par exemple, on constate ici que la date minimum du champ " date_visite_diagnostique " est le 23/07/1013. Cette erreur est manifestement une erreur de saisie sur l'année qui peut être rapidement corrigée en sélectionnant la ligne correspondant à ce minimum, puis dans la table en modifiant la valeur de la date en 23/07/2013. Une fois la mise à jour enregistrée, désélectionnez la ligne, puis recalculez les statistiques dans le panneau Data Engineering. Le diagramme de distribution des valeurs est maintenant cohérent.


4- Un autre problème peut ici être identifié sur le champ " consommation_energie " qui présente des valeurs négatives et des valeurs anormalement élevées. De la même manière que précédemment vous pouvez rapidement les corriger dans la table, par exemple ici en supprimant les lignes suspectes. Pour sélectionner les lignes correspondant à une plage de valeurs précises, vous pouvez demander à ouvrir le diagramme de distribution. Après correction, le fait de recalculer les statistiques (dans l'interface de Data Engineering) vous permet d'actualiser ce diagramme de distribution.


5- Un autre aspect de la préparation d'un jeu de données est de vérifier les types d'un champ. Par exemple ici, on constate que le champ " code_insee " est de type " Texte ", alors qu'on souhaite disposer d'un champ de type " Long " pour de futures jointures avec notre couche des communes. Pour cela, l'interface de Data Engineering ne propose pas de nouveaux outils, car ils existent déjà dans ArcGIS Pro. Deux outils vous permettent de créer un champ " code_insee_ num " de type numérique et d'y copier les valeurs par calcul de champ. Ils sont simplement rassemblés dans le groupe d'outils " Créer ", ce qui permet un gain de temps.


6- Une fois ce problème de type de champ traité, un dernier point reste à traiter dans la préparation de nos données. Il s'agit ici de classer les différentes valeurs de consommation d'énergie en 7 classes de consommation A, B, C, D, E, F et G afin de pouvoir produire des DataViz avec cette codification normalisée. Pour cela, nous utilisons l'outil " Reclasser un champ " qui se trouve dans le groupe d'outils " Mettre en forme ".


7- L'outil de reclassement permet de décrire les différents intervalles de valeurs et d'indiquer la valeur correspondante souhaitée. L'outil permet de créer les intervalles de reclassification de manière automatique par une méthode mathématique ou de manière manuelle. Nous allons prendre cette dernière option pour pouvoir définir les intervalles avec nos propres valeurs. On note que les intervalles se définissent par leur borne supérieure. L'outil permet de créer autant de classes que nécessaire. Indiquez également le nom du nouveau champ à créer.


8- Une fois l'outil de reclassement exécuté, deux champs ont été créés. Le premier est nommé avec le suffixe " CLASS". et contient les nouvelles valeurs de reclassement, le second est nommé avec le suffixe " _RANG " contient les bornes des intervalles appliqués lors du reclassement. Ceci permet notamment de garder une trace des bornes utilisées. Ce second champ peut être supprimé si vous n'en avez pas besoin.


9- Maintenant que nous disposons de nos classes de consommation d'énergie, il est intéressant de voir la répartie des classes A, B, C, etc. à l'aide du diagramme de répartition. Pour cela, il faudra ajouter le nouveau champ " consommation_energie_7_classes " dans le panneau de statistiques de l'interface de Data Engineering. Après avoir vérifié que toutes les lignes de la table sont désélectionnées, vous pouvez recalculer les statistiques. Dès lors, il suffit de survoler le diagramme de distribution pour avoir le détail de la répartition pour chaque classe. Comme nous l'avons vu précédemment, vous pouvez également ouvrir le diagramme pour plus de détails.


10- La dernière phase de notre préparation de données consiste à agréger notre table des DPE par commune afin de pouvoir cartographier certaines informations. Pour cela, nous utilisons la commande " Récapituler " que l'on trouve dans le menu contextuel du champ de récapitulation (ici le champ " code_insee_num " créé précédemment). Nous demandons notamment la moyenne de la consommation énergétique des bâtiments ayant réalisé un DPE afin de pouvoir la représenter sur une carte.


11- Une fois que la nouvelle table récapitulée est créée, vous pouvez afficher vos statistiques dans l'interface de Data Engineering, comme pour la table d'origine. Cela vous permet rapidement de valider la cohérence des valeurs de chaque champ, puis de lancer l'outil de jointure de champ afin de joindre la couche des communes avec cette table de statistiques sur les DPE. Le champ contenant le code INSEE (en numérique) permet ici de faire la jointure.


12- La jointure est maintenant réalisée sur la couche des communes. Nous disposons donc d'informations permettant de cartographier les communes du Calvados en fonction, par exemple, de la moyenne des consommations énergétiques issue des DPE de chaque commune entre 2013 et 2020. Nous avons choisi ici une représentation très simple par symboles gradués. Nous avons travaillé ici sur une table autonome, mais lorsque vous travaillez sur des tables attributaires de couches vous découvrez de nombreux autres outils pour manipuler les propriétés géographiques de vos données.
 Partager par email
Partager par email Version imprimable
Version imprimable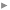 L'essentiel
L'essentiel




